Generating Long Sequences with Sparse Transformers
GPT-3で使われているという噂の、sparse attentionの論文。
説明が楽なので一旦causalityを忘れることにする。n tokensあるとする。普通のattentionでは、各tokenに対して、全n tokenにattendできる。sparse attentionでは、各tokenに対し、各headでのattend出来る場所を√n箇所に絞る。
例えば、直近√n個にattendできるheadと、√n個飛ばしでの√n個にattendできるheadがあれば、その2つを両方経由すれば任意のtokenの情報が取れる。そんな感じ。
Solving Quantitative Reasoning Problems with Language Models
Google Research
数学っぽい文章で学習したら数学っぽい問題解けるようになったという話。主に、数学っぽい学習データセットを作ったという話と、評価の話。
データセットはWebとarxiv。うちLLaMaでも使われているarxiv datasetの作り方は以下の通り。
- 複数のTeXファイルに分かれている場合、連結する
- コメントを削除する
- 最初のsection header以前、及びappendix/bibliography header以降を削除する
- タイトル・アブストラクトをarXiv metadataから追加する
- 低品質なものを削除、具体的には
- longer than 75k tokens
- had on average more than 0.6 tokens per character
- had no \section headers
- or ended up being empty after processing
- ユーザーが書いたdefinitionやmacroを展開(Googleの論文にはこの記載はないがLLaMaの論文には書かれている)
Language Models are Few-Shot Learners
GPT3の論文。
いろいろ
- アーキテクチャ、dense attentionとsparse attentionが交互?Sparse Transformerを読まないといけない
- scaling lawの元論文、パラメタ数同じぐらいだったら多少のアーキテクチャ(ヘッド数、レイヤー数、チャンネル数など)の影響が大きくないって話も乗ってるらしい KMH+20
- 勾配のノイズを見ながらバッチサイズの選択をしたらしい? MKAT18
- データセット: Common Crawl, WebText2, Books 1, Books 2, Wikipedia
Contaminationの分析
Section 4, Appendix Cにcontaminationに関する議論・分析がある。基本的には問題ではないという主張で、それをサポートするための議論が以下。
実験としては、「benchmark datasetをそのまま使って評価した場合」と「benchmark datasetから、contaminationの可能性が少しでもあるexampleを全て削除したclean datasetを作成し、それで評価した場合」を比較する。これで性能が全然変わらないからヨシ!だってお。
他の議論。
- GPT2でも問題ではなかった。ましてやパラメタ数も増えたとはいえデータももっと増えてるから覚えられるわけないじゃん。
- 学習曲線みてよ。trainとvalの差小さいからそんなoverfitしてないんだって。
具体的なclean化は、13 gramで一致があれば削除、みたいな感じ。この実験はやろうと思えばできそう。
おまけ
Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model.
草、正直でよろしい
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
host memoryやNVMeを使ったout-of-coreの実装を真面目にクソ頑張ることで、より大きなtransformerを高い実行効率を維持しながら学習できるようにする話。
手法
基本的には各種データ(param, optimizer stats, activationなど)のアクセスパターンを考える。次に、それに応じて要求される読み込みbandwidthを計算する。実行効率を維持したいので、「計算とoverlapさせられるかどうか」で要求bandwidthが決まる。あとは、それに応じてデータの配置をする。
これを気合を入れて実装する。
感想
何かびっくりするようなアイディアが有る訳ではない。それもあってか論文の書かれ方は結果が凄いことを何度もゴリ押しして強調してくるからだるい。
こうやってちゃんと必要な性能を計算して設計するアプローチは当たり前っちゃ当たり前だがすごく大事と思う。実装めちゃくちゃ大変そうなので凄い。
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
クソでかモデルでGPUがメモリ足りない時のための手法。ZeRO-DPとZeRO-Rがある。
ZeRO-DP
DP=data parallel。optimizerのstate(momentumなど)、gradient、paramを分散して持てば良い。
- stateを分散して持つ場合、各担当ワーカーくんがparamを更新した後、paramをall-gatherすればいい。
- gradientも分散して持つ場合、NNをブロックに分け、各ブロックのbackwardが終わり次第、gradientをreduce-scatterしながら進めばいい。
- paramも分散して保つ場合、各ブロックの冒頭で持ち主ワーカーくんからparamをbcastしてもらえばいい。
ZeRO-R
モデルパラレルで同じようなことをする話。省略。
感想
optimizerのstateを分担して持てる、って言われた瞬間にどうやるか分かるぐらい簡単な話な訳だが、言われるまで自分でこれが出来るって気づいてなかったのが悔しい(そういう人は多そう)。まぁモデルのパラメタサイズが問題になるような状況に今まであんま遭遇してなかったからという言い訳で一つ。
メモリ使用量と通信時間をトレードオフする手法な訳だが、通信データ量の変化しか書かれていない。実際にはlatency項もあるはずなので通信回数も一瞬気にならなくもなかったけど、全然無視できそうだな。
論文の書き方が、「概要から詳細に入っていく」みたいな流れを異様に重んじて概要がめちゃくちゃ繰り返されまくっててクソ冗長。謎。
Flamingo: a Visual Language Model for Few-Shot Learning
DeepMindの、VLM(Visual Language Model) / LMM(Large Multimodal Model)の論文。文中に画像が現れてるようなものを読んで、画像と文章の両方を加味した文章生成ができる。例えばin-context learningを通じてVisual QAなどができる。
アプローチ
- e2eではない。Vision Encoder (VE)とLanguage Model(LM)を持ってきて、それらの重みはfreezeする。
- VEの出力(W'×H'×C)を、Perceiver Resamplerというモジュールに通し定数長にする。そして、LMの各ブロックの間に、その定数長のベクトルへのcross-attentionを混ぜ込むレイヤーを追加する。
- Perceiver Resamplerは、それはそれでなんというか普通にattentionするだけ。K, Vが各パッチのベクトル(長さC)で、Qはtrainableな固定ベクトルだと理解した。(なおK, VにQをconcatenateする謎テクにより性能が少し上がるらしい)
- 混ぜ込むレイヤーの出力にはgate機能をつけ、これが最初ゼロになっとくことにより最初は元のLMと同じ出力をするのでやさしく学習できる。ControlNetとかに似とるね。
その他
- Perceiver Resamplerの機構はVision側が動画でも適用可能。計算量はやばそう。
OSS実装
8-bit Optimizers via Block-wise Quantization
背景
もともとCLIPの論文を読んでた際、"half-precision Adam statistics"という記述があって気になった。が、今はそれどころか8bitでやるこの論文の実装が結構使われてるっぽい気がする?
実装
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
最大1 trillionパラメータのtransformerを3000GPUs規模で分散学習する方法について模索するNVIDIAの論文
方法
- data parallelism……各ワーカーが同じモデルを持ち違うデータに対してfwd/bwdをして勾配を計算し、勾配をallreduceする
- model parallelism……各ワーカーがモデルの別の部分を担当する
その他、activation recomputation(gradient checkpointing)なども使う。
実装
Classifier-Free Diffusion Guidance

この調整できるguidance scaleってどういう仕組みなのか分からなくなったので調べてみた。
ImaGenの論文を見るとこう書いてある(P.4)

一見0≦w≦1で重みつき平均の式……かと思いきや、これでw>1にするらしい。それによって、よりconditionを強調するってことか。なるほど。
ImaGenの論文見るだけで納得してしまって元論文(Classifier-Free Diffusion Guidance)はまだ見てないから理解甘いかもしれない。また疑問が湧いたら戻ってくる。
FID & CLIP score
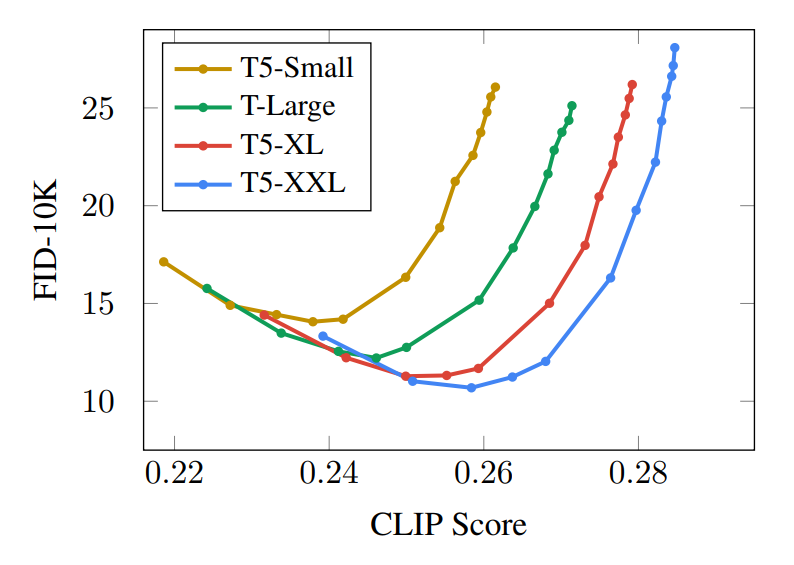
こういうやつの意味を理解する。
FID (Frechet Inception Distance)
Inception V3モデルを利用した指標。生成画像と、リアル画像の、Inception V3による出力feature vectorの分布の違いをFrechet Distanceというので計算したものっぽい。
CLIP Score
- CLIPのtext encoderにpromptを入れたembedding
- CLIPのimage encoderに生成画像を入れたembedding
これらのcosine類似度を計算したものっぽい。
FID CLIP Score Curve
画像の品質とpromptへの従い度合いのトレードオフを描いたグラフだと理解した、なるほど
guidanceの強さを変えながら描いてるものが多いと思うが、少し強くしたほうがCLIPだけじゃなくてFIDも良くなるのは、何でなんだぜ?全くguidanceが無いより少しguidanceがあったほうがそれっぽい画像が生成されるってこと?
Learning Transferable Visual Models From Natural Language Supervision
概要
CLIPの論文。CLIPのtext encoderがstable diffusionでも使われている。
画像認識の基盤モデルを作る試み。膨大な(image, text)ペアから事前学習し、ImageNet1kを含む様々なタスクをゼロショットで(classに対応するtext指定するだけで)めちゃ良い性能出せる。
方法
画像をembeddingにencodeするモデル(CNN or ViT)と、テキストをembeddingにencodeするモデル(transformer)を使う。
膨大な(image, text)ペアから、contrastive learningする。

こんな感じで、n sampleからなるミニバッチ内で、n × n のあれこれをする。embedding同士のdotを計算し、それでsoftmax cross entropyする。なんか説明がむずいな。
400 million examplesだって。
High-Resolution Image Synthesis with Latent Diffusion Models
概要
Latent Diffusionの論文。Stable DiffusionはLatent Diffusionをベースにしてる。
事前に学習したencoder-decoderを利用し、解像度の低いlatent spaceで拡散モデルを学習・推論することにより、効率化。
適当に斜め読みした感じでは、元論文であるなぁ、という感想ぐらいしか抱かなかった……
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
やりたいこと
拡散モデルにて、主題を固定してそいつに関する新しい絵を描画させたい場合の方法を提案。主題に関する画像が何枚か手に入るとする。
手法
- 基本的なアイディアは、それらの画像でfinetuneする、というだけ。
- 'sks' や 'djv' みたいな、全然使われてない単語を、その主題を指す新しい単語ということで使って覚えさせる。つまり、例えば "a photo of sks man" みたいなプロンプトでfinetuneする。
- 破壊的忘却を抑止するために、 prior-preservation lossというのを使う。"a photo of a man"で元モデルが生成した画像を、"a photo of a man"で生成させるよう、そいつも学習データに使う。
簡単だね。
後続研究
LoRAとかが今よく使われてる印象だけど、計算時間や生成物がデカくてもいいならDreamBoothの方が品質が良いという説もある?要出典
OSS実装
色々あるが、huggingface/diffusersのexampleのやつが、メモリ節約方法などのオプションが色々実装されていて一番良さそうだった。
An Introduction to Variational Autoencoders
Stable Diffusionでも使われているVAEについて復習。有名な技術なのでわかりやすい解説が色々あるだろうと色々解説を探したが、結局Kingmaご本人のこれが一番わかりやすかった。
生成モデル
- $x$: 観測されたデータ点たちの集合。
- $p^*(x)$: 真の確率分布。未知でこれを知りたいが知れない。
- $p_\theta(x)$: それを近似するもの。$\theta$は学習可能なパラメタ。
$x$が与えられた際、 $p_\theta(x) \approx p^*(x)$ となるような $\theta$ を探すことが目標。
DLVM (deep latent variable models)
- $z$: latent variable。観測できない。
- $p\theta(x) = \int{p\theta (x, z) dz}$: (single datapoint) marginal likelihood
DLVMとは、$p\theta(x, z)$ をNNを利用し表現したもの。特に $p\theta(x, z) = p\theta(z) p\theta(x|z)$ と分解し $p\theta(z)$、$p\theta(x|z)$ をそれぞれ別に考えるのが一般的。
上のmarginal likelihoodの式に積分が含まれ、直接最適化できないため、どうするか考えていく必要がある。
Encoder (or Approximate Posterior)
- $q_\phi(z | x)$: inference model。encoder, recognition modelとも呼ぶ。
- $\phi$: inference modelの学習可能なパラメタだがvariational parametersとも呼ぶ
$q\phi(z | x) \approx p\theta(z|x)$ となるよう $\phi$ を最適化したい。(何故これがあると良いのかは後述。)
DLVMと同様に、$q\phi(z | x)$ をNNを利用し表現する場合、$x$を入力とし$\phi$をパラメタとしたNNで$(\mu, \log \sigma)$を出力させ、$q\theta(z|x) = \mathcal{N}(z; \mu, diag(\sigma))$ とする。
Evidence Lower Bound (ELBO)
- $\log p\theta(x) = L{\theta, \phi}(x) + D\text{KL}(q\theta(z | x) || p_\theta(z|x))$
- $L{\theta, \phi}(x) = \mathop{\mathbb{E}}{z \sim q\phi(z | x) }[\log \frac{p\theta(x, z)}{q_\phi(z | x)}]$
この$L_{\theta, \phi}(x)$がいわゆるvariational lower bound、別名evidence lower bound (ELBO)である。
$D\text{KL}$はKLダイバージェンスね。$D\text{KL}$は非負なので、ELBOは $\log p_\theta(x)$ の下界である。
直接最適化できない(log) likelihoodの代わりとして、ELBOを目的関数として最適化すると良い!なぜならELBOはlog likelihoodの近似であり、それどころかELBOの最適化を通じて$q\phi(z|x)$は$p\theta(z|x)$に近づくため$D_\text{KL}$も最小化されるのである。
Reparameterization Trick
$z$ って確率変数が計算グラフのまっただ中に入ってるとダルいから、trainableではなくした固定した確率変数 $\epsilon$ を入力ってことにして $z$ をその関数として表現したら計算グラフの中にstochasticityがなくなっていいね。ってことだと理解した。